Today, I entered the voice room about IELTS.
and the host emphasized that reading and writing are important.
Actually, I was not with him.
As you know, Japan and Korea are famous countries for not good at English, and their educational system absolutely have focused on reading and writing.
That's why I couldn't find Korean and Japanese in his room.
I was stressed because of my English skills, so I've found a lot of "How to Improve Your English" videos.
Many people said about 'acquiring' or 'picking up' language as like 'compelling input' or 'comprehensible input' like that.
Many polyglots, who are English native speakers, insist that they didn't have to learn other language like Spanish, French, Deutch, etc.
But when it comes to Korean or Japanese, we can figure out their some asian language skills are not good.
Actually, I'm not good at English, and so whenever I said I'm bilingual, I felt something like guilty.
Now, I think this is a trap of 'acquiring'.
As I think, Korea and Japan's educational systems of Englsih have just focused on reading, not writing.
So I decided to follow his opinion one more time
-------
Today, I entered the voice room about IELTS.
and the host emphasized that reading and writing are important.
Actually, I was not with him.
As you know, Japan and Korea are famous countries for not being good at English, and their educational systems are absolutely focused on reading and writing.
That's why I couldn't find Korean and Japanese in his room.
I was stressed because of my English skills, so I've found a lot of "How to Improve Your English" videos.
Many people said about 'acquiring' or 'picking up' language as like 'compelling input' or 'comprehensible input' like that.
Many polyglots, who are English native speakers, insist that they don't have to learn other languages like Spanish, French, Dutch, etc.
But when it comes to Korean or Japanese, we can figure out that their Asian language skills are not good.
Actually, I'm not good at English, and so whenever I said I'm bilingual, I felt something like guilty.
Now, I think this is a trap of 'acquiring'.
As I think, the Korean and Japanese educational systems of English have just focused on reading, not writing.
So I decided to follow his opinion one more time.
전체 글
- Writing English for fun 2024.02.14
- SSAFY비전공 파이썬 반을 위한 자바 알고리즘 - 리스트에 여러 타입 넣기 2023.11.23
- 4. Python No module named 에러 - venv를 만들었는데도 모듈을 못찾는다? 2023.11.07
- 3. Redis로 실시간 데이터 확인 빠르게 하기 2023.10.31 1
- 2. Spring Batch 5.0을 사용해서 특정 시간마다 로직 수행하기 2023.10.30
- 1. 자바 스프링에서 클라이언트로 한국투자증권API 웹소켓 열기 2023.10.26
- Spring Boot 3.0.1 - Spring Security + JWT 회원가입 및 로그인 구현 2023.10.24
- 프로그래머스 - 합승 택시 요금(2021 KAKAO BLIND RECRUITMENT) 2023.09.15
Writing English for fun
SSAFY비전공 파이썬 반을 위한 자바 알고리즘 - 리스트에 여러 타입 넣기
SSAFY 1학기를 비전공 파이썬으로 마치고 나면 파이썬으로 알고리즘을 풀이하는 것에 익숙해지게 됩니다.
하지만, 요즘 기업에서 파이썬이 아닌 자바로만 코딩테스트를 보는 기업들이 점점 늘어나고 있어,
파이썬으로만 알고리즘 문제를 풀었던 친구들이 코딩테스트 때문에 입사지원을 포기하게 되는 경우를 종종 보게 됩니다.
하지만, 파이썬으로 알고리즘 문제를 풀 수 있다면, 로직을 짤 수 있는 사고 및 추론 능력은 충분합니다.
자바로 해당 코드를 어떻게 짜야하는가만 알면 금세 자바로 코딩테스트를 통과할 수 있을겁니다.
제가 느꼈던 "파이썬으로는 이렇게 풀면 되는데 자바로는 어떻게 코드를 짜야하지?" 의 생각들을
정리해둔다면 다른 비전공자 학생들도 자바로 코딩테스트를 무난하게 풀 수 있을 것이라 생각하여 글을 작성하게 되었습니다.
파이썬과 자바의 가장 큰 차이는 정적언어와 동적언어의 차이일겁니다.
lst = [] 으로 리스트를 간단하게 만들 수 있고
lst.append("1")
lst.append(1)
이렇게 다양한 타입의 언어들을 하나의 리스트에 다 넣어도 문제가 생기지 않는 파이썬에 익숙해지다보면
다양한 타입들을 리스트에 넣어야 하는 상황을 맞닥뜨리게 될 때 당황하게 됩니다.
배열보단 동적으로 가변 메모리를 갖는 리스트에 익숙하다보니 가변길이를 갖는 리스트를 찾게되고,
List<Integer> lst = new ArrayList<>(); 이렇게 만들면 간단하게 파이썬의 list와 비슷한 구현이 가능하겠구나! 라고 생각한 사람들에게 첫번째 관문이 바로 타입입니다.
문제로 예시를 들어보도록 하겠습니다.
https://school.programmers.co.kr/learn/courses/30/lessons/1844
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
전형적인 bfs문제이며, row, column, depth를 체크해주면 되는 문제입니다.
Queue<int[]> q = new LinkedList<>(); 를 사용하여 Queue를 만든 뒤, [r, c, d] 형태로 넣어도 되겠지만,
만약 d가 숫자가 아니라 문자열이라면 int[]에 담을 수 없게 되기에 난관에 봉착하게 됩니다.
그렇기에 타입을 여러개 담을 수 있는 Class에 익숙해져야 합니다.
class Solution {
public static class Player{
int row;
int column;
int depth;
public Square(){
}
}
public int solution(int[][] maps) {
int answer = 0;
Player player = new Player();
return answer;
}
}
Player 객체를 만들고, 해당 플레이어의 row, column, 그리고 몇 번 움직여서 들어갔는지 체크할 depth 변수를 갖게 해줍니다
public int bfs(Queue<Player> q, int[][] maps){
boolean[][] visited = new boolean[endRow][endColumn];
visited[0][0] = true;
while(true){
if(q.isEmpty()){
return -1;
}
Player player = q.poll();
if(player.row == endRow-1 && player.column == endColumn-1){
return player.depth+1;
}
for(int d = 0; d<4; d++){
int nr = player.row + dr[d];
int nc = player.column + dc[d];
if(isValid(nr, nc) && maps[nr][nc] == 1 && !visited[nr][nc]){
q.add(new Player(nr, nc, player.depth+1));
visited[nr][nc] = true;
}
}
}
}
bfs의 로직을 보면 Player 객체를 만들어 그 안의 값들을 조작할 수 있습니다.
이렇게 파이썬에서 list안에 담던 것들을 객체로 만들어주면 좀 더 직관적으로 자바를 이용한 코딩테스트를 치룰 수 있습니다.
이중리스트의 경우에도 대부분은 내부 리스트가 아닌 객체 하나로 처리할 수가 있습니다.
객체지향적으로 코딩테스트를 풀을 필요는 없지만, 각각의 문제에 나온 요소들을 객체로 만들어서 관리해주면 좀 더 문제를 풀기에 편해진다는 걸 생각하면
파이썬에서 자바로 코딩테스트 언어를 옮기는 것은 그렇게 어렵지 않습니다
'자바 알고리즘 기초' 카테고리의 다른 글
| 자바 기초 알고리즘 - SWEA 영어공부 이분탐색 (0) | 2023.07.01 |
|---|---|
| 자바 기초 알고리즘 - 분할정복으로 제곱 빠르게 계산하기 (0) | 2023.06.25 |
| 자바 기초 알고리즘 - LinkedList 직접 구현하기 - 2 (0) | 2023.06.09 |
| 자바 기초 알고리즘 - Linked List 직접 구현하기 (0) | 2023.06.04 |
| JAVA 기초 알고리즘 - [프로그래머스] 과제 진행하기 (여러 값을 가진 리스트? 객체 만들기! + stack) (1) | 2023.05.09 |
4. Python No module named 에러 - venv를 만들었는데도 모듈을 못찾는다?

pip list에 분명 beautifulsoup4가 있는데도 불구하고 모듈을 못 찾는 에러가 발생하는 경우가 있습니다

주식 정보를 가지고 오는 FinanceDataReader 라이브러리에 있는 beautifulsoup을 찾지 못하는 에러입니다.
에러 메세지를 보니 python39가 sys path로 되어있어 발생하는 문제입니다
이전에 파이썬 3.9버전을 사용하다 프로젝트를 위해 3.7버전으로 다운그레이드를 해놓았지만, 사용하는 라이브러리는 여전히 3.9버전과 연동이 돼있어서 생기는 문제입니다
그럼 3.9버전에는 해당 모듈이 깔려있지 않다는 걸까요? 확인해보아야 할 것 같습니다
python39 폴더 안의 scripts 폴더에서 pip list를 사용해보니

bs4 모듈이 깔려있지 않은걸 알 수 있습니다
이곳에서 pip install beautifulsoup4 을 다운로드 받아주면?

bs4가 아닌 다른 모듈이 필요하다는 문구를 볼 수 있습니다
python39에서 불러오는 것이 아닌 python37을 기준으로 불러왔으면 좋겠는데,
일단 이 방법으로 모듈을 못 찾는 문제를 해결한 뒤, 그 방법을 알아내어 추후에 수정해야겠습니다
그런데 가상환경에 있음에도 불구하고 39버전의 라이브러리를 찾는건 여전히 문제입니다.
근본적인 원인이 해결이 되지 않은 것이죠.
가상환경 안에 있는 모듈을 사용해야하는데, 가상환경으로 설치한 모듈을 가져올 수 있게 하는 방법을 알아 내야할 것 같습니다.
***
uvicorn을 가상환경에 설치하지 않았다보니, uvicorn부터가 가상환경에서 실행이 되지 않았고 uvicorn을 이전에 깔았던 3.9버전에서 불러오는게 큰 문제였던 것 같습니다
가상환경에서 다시 uvicorn과 fastapi를 다운로드 받아주니, 가상환경에서 필요한 모듈을 불러오는 것을 볼 수 있었습니다.
'주식자동매매프로젝트' 카테고리의 다른 글
| 3. Redis로 실시간 데이터 확인 빠르게 하기 (1) | 2023.10.31 |
|---|---|
| 2. Spring Batch 5.0을 사용해서 특정 시간마다 로직 수행하기 (0) | 2023.10.30 |
| 1. 자바 스프링에서 클라이언트로 한국투자증권API 웹소켓 열기 (0) | 2023.10.26 |
3. Redis로 실시간 데이터 확인 빠르게 하기
1. Redis 설치
https://github.com/tporadowski/redis/releases
Releases · tporadowski/redis
Native port of Redis for Windows. Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Se...
github.com
이곳에 들어가 Redis를 설치해주었습니다. msi 파일을 설치해주고 port번호를 6379로 설정해줍니다.

그 후 Build.gradle에서 의존성을 넣어주면 스프링 부트에서 redis를 사용할 수 있게 됩니다
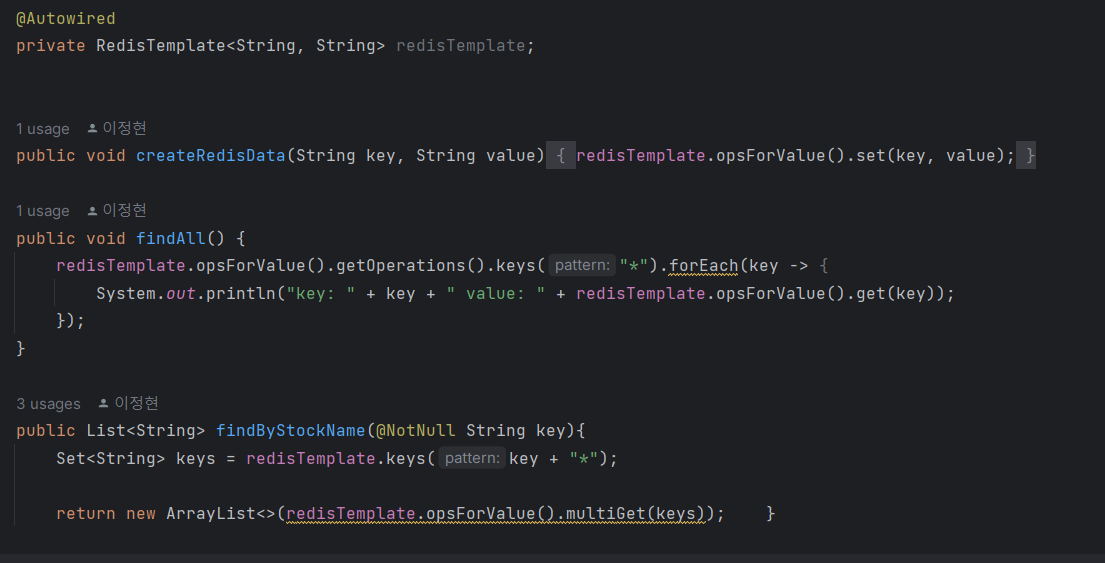
2. redisTemplate으로 redis 사용하기

RedisTemplate Bean을 주입받아 바로 사용해보도록 하겠습니다.
redisTemplate의 opsForValue 메서드를 이용하여 set과 get을 할 수 있고, 여러개의 key 패턴을 넣을 수도 있습니다.
사용자가 저장해둔 DB의 값을 계속적으로 확인하기 위해 RDBMS에 계속 접근하는 것은 굉장히 불편한 일이라고 생각이 들었습니다.
실시간으로 데이터가 날라올 때마다 DB에 접근을 한다면 CP 문제가 생길 것입니다.
Redis를 이용해 캐시 메모리에 저장을 해두고, DB에 접근할 필요 없이 실시간으로 데이터를 체크해 줄 수 있게 됐습니다.
만약 사용자가 저장해둔 DB값에 변화가 발생한다면 Redis를 업데이트 시켜주고, 그 외에는 기존에 있던 Redis를 사용한다면 꽤 그럴듯한 자동 시스템이 만들어질 것 같습니다
'주식자동매매프로젝트' 카테고리의 다른 글
| 4. Python No module named 에러 - venv를 만들었는데도 모듈을 못찾는다? (0) | 2023.11.07 |
|---|---|
| 2. Spring Batch 5.0을 사용해서 특정 시간마다 로직 수행하기 (0) | 2023.10.30 |
| 1. 자바 스프링에서 클라이언트로 한국투자증권API 웹소켓 열기 (0) | 2023.10.26 |
2. Spring Batch 5.0을 사용해서 특정 시간마다 로직 수행하기
1. Spring batch를 사용해서 Job과 Step을 만들고, Tasklet을 수행하게 만들기
- Job 만들기
JobConfiguration을 만들어 job과 step을 bean으로 만들어주도록 하겠습니다
Bean을 관리하는 Configuration이니 @Configuration을 붙여주저야겠죠?

JobBuilder를 통해 Job을 만들어주도록 합니다.
해당 Job의 이름은 getStockInfo2입니다. 이 이름들은 jobRepository에 의해 관리됩니다.
이 repository를 통해 job의 이름들도 관리되고, 중복 실행도 방지되는 등의 역할을 하게 되는 듯 합니다.
start에는 해당 job이 처음으로 실행할 step을 넣어주고 build하여 반환해줍니다.
- Step 만들기

이번엔 step입니다.
Job과 마찬가지로 StepBuilder를 통해 만들고, jobRepository로 관리합니다.
해당 step은 tasklet을 수행하게 됩니다.
tasklet은 Transactional하게 관리되어야 합니다. 그렇기에 transactionManager도 넣어줍니다.
- Tasklet 만들기

Step은 Tasklet을 수행합니다.
이 Tasklet을 구현한 구현체에 execute 메서드를 오버라이딩 해주면 이 메서드가 실행되게 됩니다.
return 으로 RepeatStatus.FINISHED를 반환하면 해당 Step은 일을 끝마치게 됩니다.
RepeatStatus.CONTINUABLE을 사용하게 되면 execute가 계속해서 실행되고, execute안에 if문을 사용하여 특정 지점까지 로직을 수행한 뒤 FINISHED하게 만들 수도 있습니다.

이후에 @Component를 하나 만들고 @EnableScheduling 어노테이션을 붙이면 Scheduled를 이용하여 특정 시점에 해당 Job을 실행시키게 만들 수 있습니다.
Job은 중복해서 실행이 불가능하므로, LocalDateTime.now를 이용해 Parameter를 계속해서 바꿔주었습니다.
Parameter가 달라지면 같은 JobName이더라도 중복해서 실행이 가능하게 됩니다.
이렇게 cron으로 1분 단위로 runJob을 실행시키거거나 매일 아침 6시에 해당 Job이 실행되게 만들 수도 있습니다.
하지만 이 Tasklet은 Transactional하게 관리가 된다고 하였습니다.
즉, 10000개의 데이터를 넣는 작업을 할 경우 해당 tasklet을 진행하던 도중 9999번째에서 에러가 나게 되면 이전의 모든 데이터는 유실되게 됩니다.
해당 문제를 해결하기 위해 같은 로직이라 하더라도 chunk로 단위를 쪼개어 실행하는 것이 일반적이라고 합니다.
하지만, 저희는 50개의 종목 데이터만 받아올 것이기 때문에 간단하게 batch를 돌려보았습니다.
'주식자동매매프로젝트' 카테고리의 다른 글
| 4. Python No module named 에러 - venv를 만들었는데도 모듈을 못찾는다? (0) | 2023.11.07 |
|---|---|
| 3. Redis로 실시간 데이터 확인 빠르게 하기 (1) | 2023.10.31 |
| 1. 자바 스프링에서 클라이언트로 한국투자증권API 웹소켓 열기 (0) | 2023.10.26 |
1. 자바 스프링에서 클라이언트로 한국투자증권API 웹소켓 열기
주식을 자동매매하기 위해서 한국 투자증권 API를 사용하기로 했습니다.
해당 API에서 WebSocket을 열어주는 기능을 찾았고, 실시간 호가의 변화를 계속 받을 수 있었습니다.
실시간으로 호가가 변할 때마다, DB에 저장해둔 값과 비교를 하고,
해당 가격과 일치하게 된다면 매수/매도 를 진행하게 된다면 자동매매가 이루어 질 수 있을 것이라는 설계를 하고,
자바스크립트가 아닌, 스프링에서 웹소켓을 열어 한국투자증권 서버로부터 데이터를 받아와보겠습니다.
1. 클라이언트가 되어 Request를 요청할 준비

Config 파일을 클래스를 하나 만들어줍니다.
해당 객체는 WebSocketConfigurer의 구현체가 되어 빈으로 주입이 될 예정입니다.

해당 인터페이스는 registerWebSocketHandlers 하나만 구현해주면 되는 인터페이스네요.
해당 메서드를 구현해주면 앱이 실행될 때 해당 웹소켓을 열게 됩니다.

WebSocketClient 객체는 WebSocket Request를 보낼 때 필요한 객체입니다.
WebSocketConnectionManager에 webSocketClient를 넣고, 응답을 받았을 때 메세지를 처리해줄 Handler를 하나 만들어 넣습니다. 그리고 url을 보내면 WebSocket Request를 할 준비가 완료됐습니다.
여기서 잠깐, ConnectionManager 객체를 확인해보고 가겠습니다.
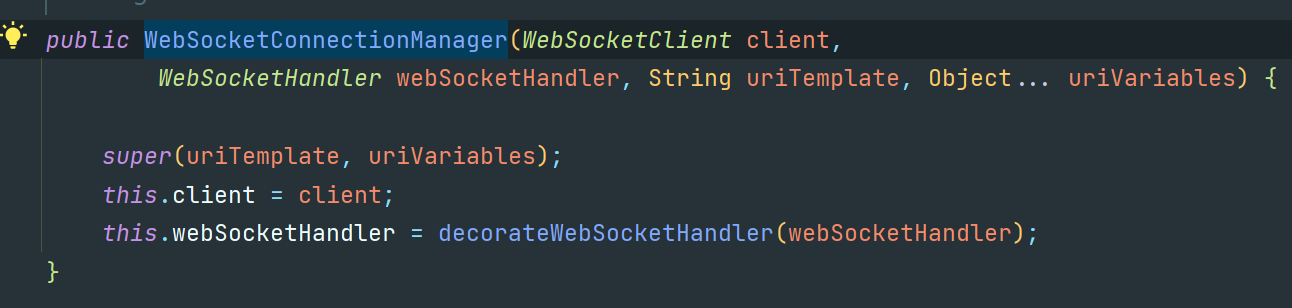
WebSocketClient는 저희가 이미 넣어줬고, WebSocketHandler는 이제 만들어서 넣어줘야할텐데요.

이 핸들러 인터페이스의 구현체는 이미 만들어져있습니다.

이렇게 추상 클래스로 구현이 되어있고,

그 추상클래스는 이 두 클래스에서 상속을 받고 있네요.
저희는 실시간 호가 Text Data가 필요하니 TextWebSocketHandler를 상속받아 WebSocketHandler 구현체를 만들어 줄 수 있습니다.

상속받은 클래스의 afterConnectionEstablished를 오버라이딩 해주어 저희가 원하는 작업을 해주도록 합니다.
해당 메서드는 윗단에서 자동으로 호출되며 session을 매개변수로 받게됩니다.
해당 session을 저희가 만든 handler에 저장시키고, TextWebSocketHandler가 가지고 있는 afterConnectionEstablished도 실행시킨 뒤, 저희가 원하는 로직을 추가로 작성합니다.
이렇게 로직을 작성한 뒤 session의 sendMessage 메서드를 실행하게 되면 웹소켓 요청이 실행되게 됩니다.

또한 handleTextMessage를 통해 response값도 받아올 수 있게 됩니다.
웹소켓은 REST API와 다르게 header와 body의 구분이 없다고 합니다 .
하지만 한국투자증권은 header와 body를 나눠서 데이터를 입력받고 있기 때문에 JSON타입으로 보내야할텐데,
자바로 이걸 어떻게 처리할 수 있을까요?
2. JAVA에서 JSON만들기
한국투자증권 API 서버에 JSON으로 request를 만들기 위해 json과 비슷한 map을 사용하였습니다.

header와 input은 Map<String, String>, input을 담은 body는 Map<String, Map<String, String>>로 설정해줍니다.
그리고 이 두개를 합쳐야하는데...

상위 클래스인 Object로 모두 받아주도록 하였습니다.
이렇게 모아놓은 Map을 json으로 바꿔주어야 합니다.
objectMapper을 사용해 String으로 바꿀 수가 있게 됩니다.
해당 문자를 TextMessage이 담아 보내면 Websocket Request가 성공하게 됩니다.
'주식자동매매프로젝트' 카테고리의 다른 글
| 4. Python No module named 에러 - venv를 만들었는데도 모듈을 못찾는다? (0) | 2023.11.07 |
|---|---|
| 3. Redis로 실시간 데이터 확인 빠르게 하기 (1) | 2023.10.31 |
| 2. Spring Batch 5.0을 사용해서 특정 시간마다 로직 수행하기 (0) | 2023.10.30 |
Spring Boot 3.0.1 - Spring Security + JWT 회원가입 및 로그인 구현
회원가입
1. Member Entity 만들기

가장 먼저 Member Entity를 만듭니다.
해당 Entity로 username과 password를 받아 회원가입을 할 예정입니다
2. 회원가입 요청을 받을 request dto를 만들고 controller를 이용해 맵핑시키기

MemberCreateRequest를 통해 username과 password를 입력 받습니다.
저는 추가적으로 한국투자증권 api를 사용하기 위해 appkey와 appsecretKey를 받아줬지만, 기본적인 회원가입에는 신경 쓰지 않아도 됩니다.
이제 createMember에서 어떤 일이 일어날지를 확인하러 갑시다
3. Spring Security가 제공해주는 PasswordEncoder를 이용하여 비밀번호 인코딩해주기

PasswordEncoder Bean을 주입받아 Repository를 이용하여 save 해줍니다.
회원가입은 이렇게 간단하게 정리할 수 있습니다.
이제 로그인을 봅시다
로그인
1. 로그인 Service 만들기
request와 controller 부분은 생략하고 Login Service가 어떻게 작동하는지를 알아봅시다

Spring Security는 UsernamePasswordAuthenticationToken 이라는 클래스를 제공합니다
username과 password를 입력받아 토큰을 만들어주죠
request에 담겨있는 유저의 id와 password를 넣고 Token을 만듭니다
request의 toAuthentication() 함수에는

다음과 같이 해당 객체를 new 해서 반환해줍니다.
여기서 이 객체가 생성될 때, username과 password를 이용해서 어떻게 이 객체를 생성할까요?
2. UserDetailsService 구현체 만들기
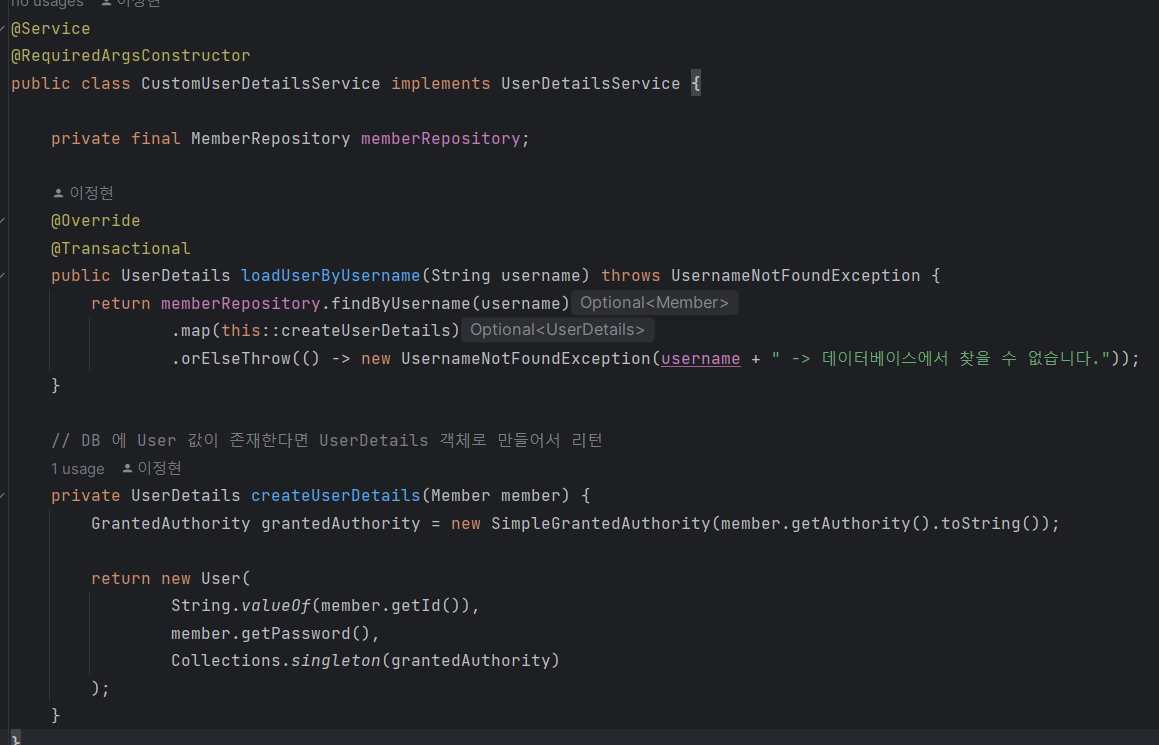
이렇게 UserDetailsService를 구현한 구현체를 이용해 토큰을 만듭니다.
memberRepository에서 username을 받아와 UserDetail을 만듭니다.
그럼 이제 이 만들어진 UserDetail을 이용해서 인증 처리를 해주어야겠죠

UserDetailsService의 구현체를 통해 얻은 Token으로 이제 DB에 있는 password와 비교를 한 뒤 로그인을 처리할지 말지 결정해야합니다.
그걸 도와주는 것이 바로 authenticationManagerBuilder입니다. 해당 토큰으로 정보를 확인하고 아이디와 비밀번호가 일치하지 않으면 예외를 던질것이고, 일치한다면 authentication 객체를 반환합니다.
만약 예외가 발생하지 않았다면 다음 단계로 넘어가서 token을 생성해줍니다.
3. JWT Token 만들기

Authroties로 member에서 설정한 Authority값을 받아옵니다.
여러 권한을 가지고 있을 수 있으니 저렇게 GrantedAuthority 객체의 getAuthority 메서드를 이용해 권한들을 모두 받아옵니다.
그리고 권한과 username 각종 요소들을 추가해 jwt token을 생성합니다.
이제 이 토큰을 이용해 인증 처리를 할 토큰을 만들 수 있게 됩니다.
jwt 토큰은 만들었는데, 이 토큰이 유효한 지 어떻게 알 수 있을까요?
로그인을 할 때 해당 토큰을 발급 한 뒤 front쪽에서 해당 토큰을 header에 넣어서 준다면, 토큰을 이용해 권한 및 인가처리를 해주어야할 텐데 말이죠
4. JWT 토큰 유효성 검사 메소드 만들기

토큰 값을 받은 뒤 Jwts 객체의 parserBuilder를 사용하여 jwt secret키를 디코딩하고 비밀키를 이용해 만든 key값을 넣어 유효성 검사를 할 수 있습니다.
5. JWT 토큰이 유효하다면 인가처리해주기

authorities는 claims의 AUTHORITIES_KEY를 통해 가져올 수 있지만, 일단 하드하게 ROLE_USER 권한을 부여하겠습니다.
그리고 UserDetails 구현체를 만들어 맨처음 로그인 했을 때와 마찬가지로 Token을 발급합니다
6. Filter 실행하기
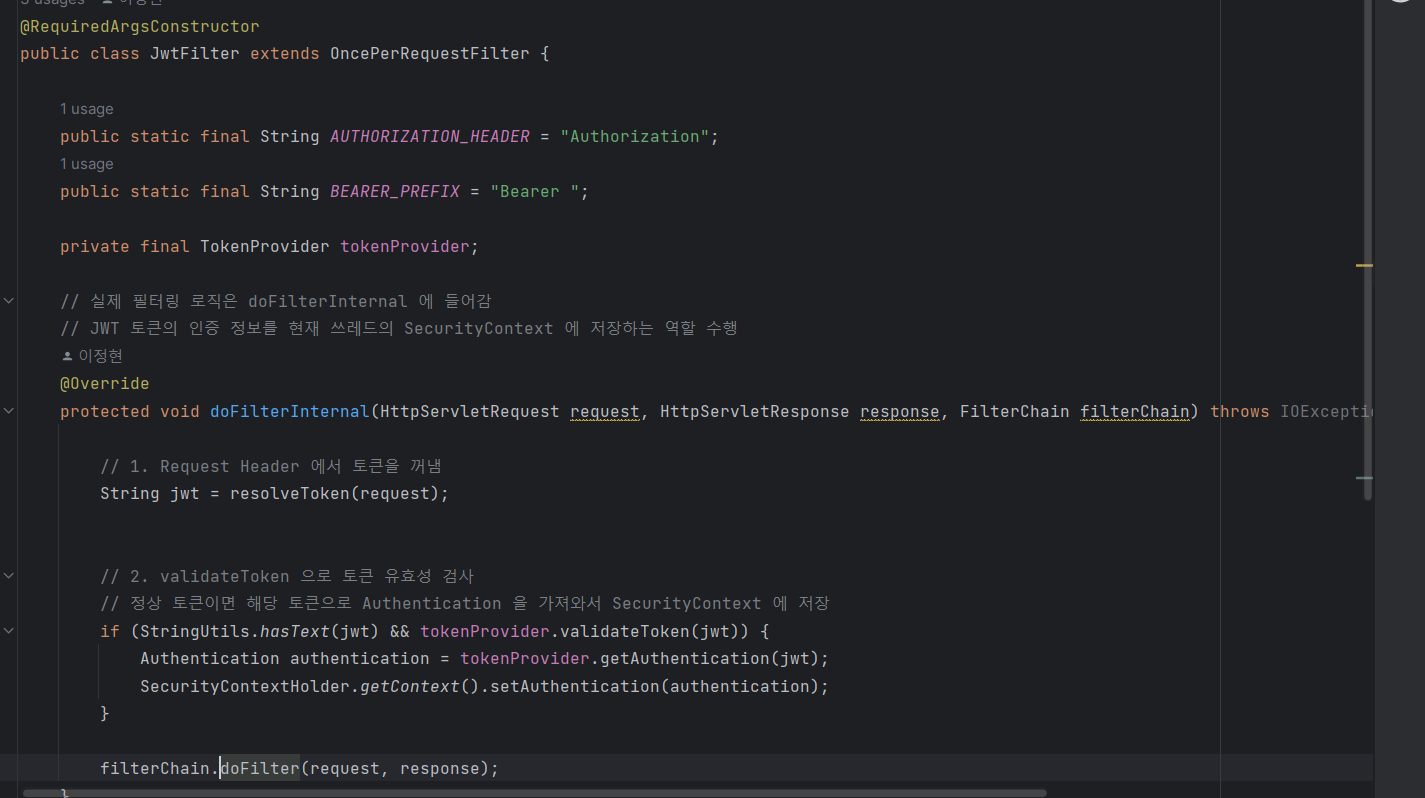
이제 JwtFilter를 만들어줍니다. 해당 OncePerRequestFilter를 상속받아, filter는 요청이 올 때 먼저 실행되어 jwt 토큰이 있는지, 유효한지를 체크하고 권한을 부여할 것입니다.
SecurityContextHolder에 authentication도 지정해고 해당 filter를 실행시키도록 doFilter를 이용해주면 로그인 처리가 되게 됩니다.
'백엔드 > Spring' 카테고리의 다른 글
| 스프링일기 14 - JPA(5) JOIN (0) | 2023.06.19 |
|---|---|
| 스프링 일기 13 - JPA(4) Main에서 사용해보기 (1) | 2023.06.19 |
| 스프링 일기 12 - JPA(3) Create2 DTO 분석하기 (0) | 2023.06.16 |
| 스프링 일기 8 - JPA(1) (SQL과 OOP 자바의 패러다임 불일치) (0) | 2023.06.14 |
| 스프링 일기 7 - Interceptor (0) | 2023.06.14 |
프로그래머스 - 합승 택시 요금(2021 KAKAO BLIND RECRUITMENT)
길 찾기 알고리즘은 Dijkstra밖에 몰랐기에, 당당하게 dijkstra로 풀었지만, 효율성 검사에서 2개가 틀리는 바람에 새로운 알고리즘을 알게 됐다.
새롭다고 해야할까... 플로이드-워셜 알고리즘을 공부하고 나니 이렇게 간단한 접근방법이 있었다니... 정신이 멍해졌다.
Dijkstra로 풀었던 코드
import java.util.*;
class Solution {
static class Graph{
int V;
List<List<Node>> adj = new ArrayList<>();
public Graph(int V){
this.V = V;
for(int i=0; i<=V; i++){
adj.add(new ArrayList<>());
}
}
public void addEdge(int start, int end, int weight){
adj.get(start).add(new Node(end, weight));
adj.get(end).add(new Node(start, weight)); // 양방향 그래프이므로 역방향도 추가
}
public int[] dijkstra(int startVertex){
int[] dist = new int[V+1];
PriorityQueue<Node> pq = new PriorityQueue<>((a, b)->a.weight - b.weight);
Arrays.fill(dist, Integer.MAX_VALUE);
dist[startVertex] = 0;
pq.add(new Node(startVertex, 0));
while(!pq.isEmpty()){
int currentVertex = pq.poll().vertex;
List<Node> lst = adj.get(currentVertex);
for(Node node : lst){
int vertex = node.vertex;
int weight = node.weight;
int currentAdjDist = dist[currentVertex] + weight;
if(currentAdjDist < dist[vertex]){
dist[vertex] = currentAdjDist;
pq.add(new Node(vertex, currentAdjDist));
}
}
}
return dist;
}
}
static class Node{
int vertex;
int weight;
public Node(int vertex, int weight){
this.vertex = vertex;
this.weight = weight;
}
}
public int solution(int n, int s, int a, int b, int[][] fares) {
int answer = Integer.MAX_VALUE;
Graph graph = new Graph(n);
for(int[] fare : fares){
graph.addEdge(fare[0], fare[1], fare[2]);
}
int[] allDist = graph.dijkstra(s);
for(int i=1; i<=n; i++){
int AB = allDist[i];
int A = allDist[a];
int B = allDist[b];
answer = Math.min(AB + A + B, answer);
}
return answer;
}
}
어느 지점까지 합승하는게 유리한지 그리디한 방법으로 알 수가 없어, 그냥 모든 경우의 수를 다 구해놓은 뒤 최솟값을 구하기로 했다.
합승하는 위치 AB에서 A와 B를 다시 dijkstra를 돌려 구해야 했는데, AB의 위치는 모든 노드를 체크해야하므로, 시간 복잡도를 O(V * (V+E) logV)로 계산했다.
간선의 최대 개수는 V^2이므로 O(V^3logV)라고 예상했는데 노드개수가 200개니까 문제없을거라고 생각했다.
하지만 예상보다 훨씬 시간이 오래 걸렸고, 다른 알고리즘을 물어보니 플로이드워샬 알고리즘이라는 것이 있다고...
class Solution {
public int solution(int n, int s, int a, int b, int[][] fares) {
int INF = Integer.MAX_VALUE;
int[][] dist = new int[n+1][n+1];
// 초기화
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(i == j) dist[i][j] = 0;
else dist[i][j] = INF;
}
}
// fares 정보로 초기화
for(int[] fare : fares) {
int c = fare[0];
int d = fare[1];
int f = fare[2];
dist[c][d] = f;
dist[d][c] = f; // 양방향
}
// 플로이드-와샬 알고리즘
for(int k = 1; k <= n; k++) {
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= n; j++) {
if(dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
}
}
}
}
int answer = INF;
for(int k = 1; k <= n; k++) {
int temp = dist[s][k] + dist[k][a] + dist[k][b];
if(temp < answer) answer = temp;
}
return answer;
}
}dijkstra와 매우 비슷한 알고리즘인 듯 한데, startVertex에서 vertex까지의 distance를 구하기 위해선 dijkstra가 좋지만
모든 노드 쌍의 최단거리를 구해야 할 때는 플로이드워샬이 더 낫다고 한다.
각 노드마다 dijkstra를 돌려야하니까 오히려 시간이 펑...
좋은걸 배웠다